[0x00] Overview
가장 최신 버전인 Unreal 4.26.1 의 샘플 빌드를 이용하여, 오브젝트 덤프를 생성하도록 하겠습니다.
해당 덤퍼는 튜토리얼 용으로, 언리얼 엔진 4.26.1 버전의 환경에서 샘플 게임을 빌드하여 테스트하였습니다.
예제에 사용된 소스코드는 추후 공개됩니다.
[0x01] Name Dump
현재 게임에 할당된 모든 Name 을 찾기 위해서는 앞서 말한대로, FNames 라고 잘 알려진 오브젝트를 확인해야 합니다.
먼저 4.26.1 기준으로 NamePoolData 를 패턴을 찾습니다.(외부에 잘 알려진 패턴 스캔 라이브러리를 사용하십시오)
ReClass 를 이용하여 아래와 같이 정의할 수 있습니다.

NamePoolData 아래와 같은 구조로 이루어져 있습니다.(UE 4.26.1 NameTypes.h 참조)
struct FNameEntryAllocator{
mutable PVOID Lock;
unsigned int CurrentBlock;
unsigned int CurrentByCursor;
PVOID Blocks[FNameMaxBlocks];
}
struct FNamePool{
FNameEntryAllocator Entires;
...
}
여기서 Blocks 는 각 Name Pool 의 블록으로 이해할 수 있습니다. 해당 블록에는 FNameEntry 으로 이루어진 각각의 엔트리가 존재합니다.
FNameEntry 는 아래와 같은 구조로 이루어져 있습니다.
struct FNameEntryHeader {
USHORT bIsWide : 1;
USHORT Len : 15;
};
struct FNameEntry {
FNameEntryHeader Header;
union
{
char AnsiName[NAME_SIZE];
wchar_t WideName[NAME_SIZE];
};
}
잠시 위의 내용을 보고 고민해보면, 덤프를 위한 모든 준비가 되었음을 알 수 있습니다.
Name Pool 의 블록 수를 알 수 있고, 각 엔트리가 어떻게 이루어진지도 알 수 있습니다.
[0x02] Name Dump Tutorial
이제 구현해야 할 것은 각 이름들을 길이만큼 복사하고, 포인터를 옮기고, 파일에 저장하는 일입니다.
여기서 이름의 길이와, 다음 포인터를 구하기 위한 공식이 필요합니다. 언리얼 엔진 소스에는 이러한 공식들이 친절하게 설명되어 있으며, 구현되어 있습니다.
이러한 정보들과 약간의 노력이면 쉽게 덤프를 생성할 수 있습니다.
먼저 FNameEntry 를 살펴 보겠습니다.
2A 01 4E 6F 6E 65 08 03 ; None
42 79 74 65 50 72 6F 70 ; ByteProp
2바이트의 헤더와 문자열로 이루어져 있습니다. 정확히는 FNameEntryHeader 와 문자열 입니다.
0x12A 가 헤더이고, None 이 해당 문자열로 유추할 수 있지만, 보는 것과 같이 널 바이트가 있거나 문자열의 끝을 알리는 어떠한 내용도 없습니다.
먼저 문자열의 길이를 구하는 공식은 아래와 같습니다.
Length = (Header >> 1) << 1 // len is 15 bit
Length = Length >> 6
Header 내 bIsWide 1비트를 지우고, 순수한 길이 값을 계산하는 것 입니다. 물론 bIsWide 값에 따라 Length * 2 로 길이를 계산할 수 있습니다.
다음은 FNameEntry 의 실제 크기를 구하는 것 입니다. 이는 언리얼 엔진 소스코드 내 alignment 와 관련된 함수에서도 찾아볼 수 있습니다.
int EntrySize =
Length + alignof(FNameEntryHeader) +
FNameAllocator::Stride - 1) & ~(FNameEntryAllocator::Stride - 1);
이제 위의 계산들을 토대로 아래와 같이 블록 당 모든 엔트리를 순회하며 이름을 가져올 수 있습니다.
BOOLEAN Dumper::NameDump()
{
DWORD BlockSize = 0, NameCount = 0;
if (!(BlockSize = DumperData.FNameData->GetBlockSize())) { return FALSE; }
for (int idx = 0; idx < BlockSize + 1; idx++)
{
FNameEntry* NamePtr = NULL;
NamePtr = Read<FNameEntry*>(&DumperData.FNameData->Entries.Blocks[idx]);
NameCount += NamePtr->GetNameDump();
}
...
...
}
DWORD FNameEntry::GetNameDump()
{
...
...
for (int i = 0; i < FNameEntryAllocator::BlockSizeBytes; i++)
{
FNameEntry NameEntry = { 0, };
NameEntry = Read<FNameEntry>(pNameEntry);
if (!NameEntry.GetName()) { break; } // Get name and Save name
Size = NameEntry.GetEntrySize(); // Get entry size
pNameEntry = (PVOID)((DWORD64)pNameEntry + Size); // next entry pointer
NameId = NameId + Size / FNameEntryAllocator::Stride;
Count++;
}
return Count;
}

[0x03] Object Dump
Object Dump 의 경우에도 마찬가지로 언리얼 엔진 내 소스코드를 활용하면 쉽게 구현할 수 있습니다.
먼저 우리는 FUObjectArray 타입의 GUObjectArray 라는 심볼릭 변수가 있다는 것을 알고 있습니다. 이 점을 이용하여 먼저 해당하는 패턴을 찾고 활용해야 합니다.
다음은 언리얼 엔진 소스코드를 참조하여 만든 클래스들의 미니멀 버전입니다.
struct UObject {
PVOID VTable;
EObjectFlags ObjectFlags;
DWORD InternalIndex;
UObject* ClassPrivate;
FName NamePrivate;
UObject* OuterPrivate;
std::string GetFullName(FNamePool* NamePoolData);
std::string GetNameByIndex(FNamePool* NamePoolData, DWORD NameIndex, bool bClass);
DWORD GetNameIndex();
};
struct FUObjectItem {
UObject* Object;
DWORD Flags;
DWORD ClusterRootIndex;
DWORD SerialNumber;
DWORD Reserved;
};
typedef struct FChunkedFixedUObjectArray {
enum
{
NumElementsPerChunk = 64 * 1024,
};
FUObjectItem** Objects;
FUObjectItem* PreAllocatedObjects;
DWORD MaxElements;
DWORD NumElements;
DWORD MaxChunks;
DWORD NumChunks;
DWORD GetObjectNum();
DWORD GetObjectChunk();
UObject* GetObjectPtr(DWORD index);
BOOLEAN IsValidIndex(int index);
}TUObjectArray;
struct FUObjectArray {
DWORD ObjFirstGCIndex;
DWORD ObjLastNonGcIndex;
DWORD MaxObjectsNotConsideredByGC;
BOOLEAN OpenForDisregardForGC;
TUObjectArray ObjObjects;
};
// Object dump
BOOLEAN Dumper::ObjectDump()
{
... // 생략
TUObjectArray ObjObjects = Read<TUObjectArray>(&DumperData.ObjectData->ObjObjects);
... // 생략
}
교육용이기 때문에 정석대로 진행하지만, 실제로 ObjObjects 에 대한 패턴을 구해 단번에 접근도 가능합니다.
[0x04] Object Dump Tutorial
현재는 GUObjectArray->ObjObjects.Objects 와 같이 접근하고 있지만 앞에 한 단계를 생략 가능합니다. 이전 챕터에서 ReClass 를 이용하여 본 내용은 아래와 같습니다.
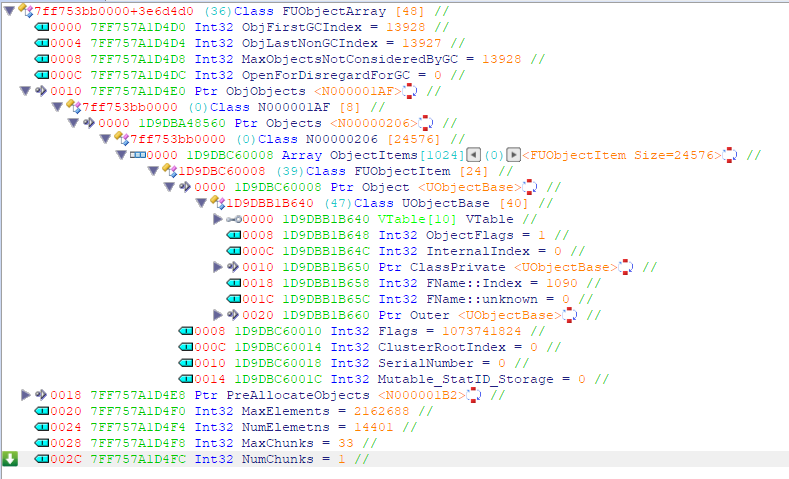
모든 오브젝트에 대한 덤프를 생성하기 위해선 Objects 내 존재하는 모든 오브젝트들에 대한 순회가 필요합니다.
DWORD FChunkedFixedUObjectArray::GetObjectNum()
{
return this->NumElements;
}
UObject* FChunkedFixedUObjectArray::GetObjectPtr(DWORD index)
{
DWORD ChunkIndex = index / NumElementsPerChunk;
DWORD WithinChunkIndex = index % NumElementsPerChunk;
if (!IsValidIndex(index)) { ErrLog("Invalid object index\\n"); return nullptr; }
if (!(ChunkIndex < this->NumChunks)) { ErrLog("Invalid chunk index\\n"); return nullptr; }
FUObjectItem* Chunk = Read<FUObjectItem*>(&this->Objects[ChunkIndex]);
FUObjectItem* Object = Read<FUObjectItem*>(Chunk+WithinChunkIndex);
return (UObject*)Object;
}
BOOLEAN Dumper::ObjectDump()
{
... // 생략
for (int i = 0; i < ObjObjects.GetObjectNum(); i++)
{
char szBuff[256] = { 0, };
UObject* pObject = ObjObjects.GetObjectPtr(i);
UObject Object = Read<UObject>(pObject);
if (Object == nullptr) { continue; }
std::string ObjectFullName = Object.GetFullName(DumperData.FNameData);
... // 생략
ObjectCount++;
}
... // 생략
}
마찬가지로 엔진 내 소스코드를 참조하여 작성한 코드입니다(UObjectArray.h 내 GetObjectPtr). 우선 위와 같은 방식으로 TUObjectArray.NumElements 의 값을 구해 모든 오브젝트의 수량을 확인하고, 오브젝트 순회가 가능합니다.
남은 단계는 해당 오브젝트가 어떠한 종류인지, 어떠한 이름을 가졌는지에 대해 확인하는 것 입니다.
위의 코드에서는 GetFullName 이라는 함수를 이용합니다.
std::string UObject::GetNameByIndex(FNamePool* NamePoolData, DWORD NameIndex, bool bClass)
{
std::string Name;
FNameEntry* BlockEntry = NULL;
FNameEntry* pNameEntry = NULL;
FNameEntry NameEntry = { 0, };
DWORD Length = 0;
DWORD BlockIdx = NameIndex >> 0x10;
DWORD Offset = NameIndex & 0xFFFF;
BlockEntry = Read<FNameEntry*>(&NamePoolData->Entries.Blocks[BlockIdx]);
pNameEntry = (FNameEntry*)((DWORD64)BlockEntry + 2 * Offset);
NameEntry = Read<FNameEntry>(pNameEntry);
Length = NameEntry.GetLength();
ReadProcessMemory(
Memory::ProcessHandle,
(PVOID)((DWORD64)this + alignof(FNameEntryHeader)),
NameEntry.AnsiName,
Length,
NULL
);
... // 생략
return Name;
}
std::string UObject::GetFullName(FNamePool* NamePoolData)
{
UObject* ClassObj = this->ClassPrivate;
UObject* OuterObj = this->OuterPrivate;
DWORD NameIndex = Read<DWORD>(&ClassObj->NamePrivate.ComparisonIndex);
ClassString = GetNameByIndex(NamePoolData, NameIndex, true);
while (TRUE)
{
if (OuterObj)
{
NameIndex = Read<DWORD>(&OuterObj->NamePrivate.ComparisonIndex);
TempString = this->GetNameByIndex(NamePoolData, NameIndex, false) + "." + TempString;
OuterObj = Read<UObject*>(&OuterObj->OuterPrivate);
}
else
{
OuterString = TempString;
break;
}
}
NameIndex = this->NamePrivate.ComparisonIndex.Value;
ObjString = this->GetNameByIndex(NamePoolData, NameIndex, false);
return ClassString + " " + OuterString + ObjString;
}
간단히 살펴보면 실제 오브젝트의 이름을 구하는 함수는 GetNameByIndex 이며, 오브젝트 트레버스 코드에서 전달받은 오브젝트의 풀 네임을 찾습니다.
FName.ComparisonIndex 가 바로 오브젝트 이름의 인덱스이고, 위에서 작성한 Name Dump 를 통해 나온 인덱스와 일치합니다.
ComparisonIndex 를 이용하여 FNamePool.Blocks 의 인덱스 값을 구해 Name Pool 에서의 오브젝트 이름을 구해오면 끝입니다.
DWORD BlockIdx = NameIndex >> 0x10;
DWORD Offset = NameIndex & 0xFFFF;
위의 코드가 바로 해당 내용입니다. 단순히 인덱스를 최대 값과 연산하여, 다음 블록을 가리키게 합니다. 예를 들어 ComparisonIndex 가 65536 이면 Blocks[1] 의 첫 번째 문자열을 가리키게 됩니다.
마지막으로 중요한건 함수의 이름과 같이 풀 네임을 가져오려 합니다. 이는 SDK Generator 작성 시에도 이용됩니다.
UObject* ClassObj = this->ClassPrivate;
UObject* OuterObj = this->OuterPrivate;
위의 코드가 오브젝트의 풀 네임을 가져오기 위한 포인터 입니다. 실제로 덤프를 생성하면 아래와 같이 해당 오브젝트의 풀 네임을 획득할 수 있습니다.
[000000] [0x1D5BC1D9DE0] Package CoreUObject
[000001] [0x1D5BB0E1A80] Class CoreUObject.Object
[000002] [0x1D5BC1D95C0] Package Engine
...
[000009] [0x1D5BB0ED780] Class Paper2D.MaterialExpressionSpriteTextureSampler
[000010] [0x1D5BB0ED0C0] Class Engine.Actor
[000011] [0x1D5BB0EE500] Class Engine.Pawn
[000012] [0x1D5BB0EC100] Class Engine.Character
[000013] [0x1D5BB0EE080] Class Paper2D.PaperCharacter
...

[0x05] Conclusion
버전 별 약간의 구조적인 차이는 있지만 언리얼 엔진 소스코드는 매우 친절합니다. FName , GObject 의 기본적인 내용을 숙지하면 버전과는 상관없이 덤프를 생성할 수 있습니다.
오브젝트 덤프만으로도 활용도가 매우 높습니다. 특정 오브젝트가 이러한 이름을 가졌다라는 정보만으로도 수 많은 시도를 할 수 있습니다.
해당 문서는 완성본이 아니며, 추후 업데이트 될 예정입니다. 부족한 부분에 대한 피드백이나 궁금한 내용은 연락주세요